Arbeitsgruppe „KI + Sprache“
![]()
Leitung: Dr. Netaya Lotze
Mitglieder: Prof. Dr. Christine Dimroth, Anna Greilich, M.A. (Doktorandin), Sarah Sophie Nagel (Hilfskraft), Vera Neufeld (Masterarbeit)
Assoziierte: Prof. Dr. Gernot Bauer und Simon Proost, M.A., B.Sc. (Informatik, FH Münster)
Ehemalige: Laura Ohrndorf, M.A., Helena Budde, M.A.
Ziele und Motivation
Künstliche Intelligenzen wie Apples Assistenzsystem Siri oder Amazons Alexa halten Einzug in unseren Alltag, Chatbots und Social-Bots wie der Twitter-Bot Tay nehmen Einfluss auf öffentliche Diskurse und interaktives Spielzeug mit Dialogfunktion führt bereits unsere Jüngsten an die Interaktion mit dem artifiziellen Gegenüber heran. Hier entsteht eine völlig neue Form der Dialogizität, die wir noch kaum verstehen.
Uns ist es ein dringendes Anliegen, die linguistische KI-Forschung in Deutschland überhaupt erst als medienlinguistische Teildisziplin ins Leben zu rufen. Dazu ist derzeit eine Einführung für Studierende mit gleichem Titel als Buchpublikation in Bearbeitung (Verlag Narr). Linguistische KI-Forschung wird in der Arbeitsgruppe „KI und Sprache“ immer als „Research-Loop“ von Grundlagenforschung und der Implementierung neuer Anwendungen verstanden. Beide Aspekte werden durch die ganz unterschiedlichen Expertisen (Gesprächsforschung, Dialog-Semantik, Psycholinguistik, Informatik) in der „AG KI“ abgedeckt. Ich bin mit beiden Aspekten bestens vertraut, da ich nicht nur Feldforschung betriebe, sondern mit Dr. Torsten Siever 2010-12 bereits auch eine E-Learning-Umgebung mit virtuellem Tutor „El Lingo“ für die Leibniz Universität Hannover entwickelt habe (Preis „Campus Emerge“ 2012, Projektförderung „Leibniz KIQS“).
Mir ist es ein Anliegen, eine interdisziplinäre Nachwuchsgruppe zu leiten, da sie von Anfang an wissenschaftlich interdisziplinär sozialisiert wurde: a) durch ihre Zeit im Graduierten-Kolleg des Norddeutschen Exzellenznetzwerks „Natur des Geistes“ (2007-2009, für Promovierende der Linguistik, Kognitionswissenschaften und Informatik, Prof. Dr. Gerhard Roth) sowie b) durch ihre frühere Beschäftigung im interdisziplinären Forschungszentrum für Web Sciences „L3S“ der Leibniz Universität Hannover (2012, Prof. Dr. Wolfgang Nejdl), wo sie eng mit Informatiker*innen zusammengearbeitet und immer eine gemeinsame Sprache gefunden hat. Als Linguistin und Philosophin an der Schnittstelle zu Informatik und Psychologie bin ich auch per se eine transdisziplinäre Forscherin.
In Münster kann die AG gleichermaßen auf Expertise und Strukturen des psycholinguistischen „Centrums für Mehrsprachigkeitsforschung“ (CEMES, Prof. Dr. Christine Dimroth) und des gesprächslinguistischen „Centrums für Sprache in der Interaktion“ (CESI, Prof. Dr. Susanne Günthner) zurückgreifen sowie auf die technische Kompetenz des Instituts für „Gesellschaft und Digitales“ (GUD) der FH Münster (Prof. Dr. Gernot Bauer).
Methoden
Die Arbeitsgruppe verbindet unterschiedliche methodische Ansätze zur Analyse von Mensch-Maschine-Interaktionen, die von qualitativer Gesprächsforschung über quantitative Korpus-Verfahren bis zu psycholinguistischen und phonologischen Experiment-Designs reichen. Erst durch die methodologisch konsistent zusammengeführten Ansätze kann eine aussagekräftige Erstbeschreibung dieser neuen Form der Dialogizität auf unterschiedlichen linguistischen Ebenen erfolgen (Phonologie, Lexik, Syntax, Semantik, Dialogkohärenz, Userperzeption, medienlinguistische Faktoren), die stets Grundlage für jegliche Diskussion der Potenziale und Gefahren dieser innovativen Technologien sein sollte. Im letzten Schritt überprüfen wir auch die Anwendbarkeit unserer Forschungsergebnisse in neuen Bots, die wir in Usability-Studien ihrerseits evaluieren. Unseren Ansatz konnten wir 2019 auf der IDS-Tagung (Institut für deutsche Sprache) in der Methoden-Ausstellung „Kaleidoskop“ vorstellen.

Abbildung 1: Research-Loop

„Mir ist es ein Anliegen eine interdisziplinäre Nachwuchsgruppe zu leiten, da ich von Anfang an wissenschaftlich interdisziplinär sozialisiert wurde: a) durch meine Zeit im Graduierten-Kolleg des Norddeutschen Exzellenznetzwerks „Natur des Geistes“ (2007-2009, für Promovierende der Linguistik, Kognitionswissenschaften und Informatik, Prof. Dr. Gerhard Roth) sowie b) durch meine frühere Beschäftigung im interdisziplinären Forschungszentrum für Web Sciences „L3S“ der Leibniz Universität Hannover (2012, Prof. Dr. Wolfgang Nejdl), wo ich eng mit Informatiker*innen zusammengearbeitet und immer eine gemeinsame Sprache gefunden habe. Als Linguistin und Philosophin an der Schnittstelle zu Informatik und Psychologie bin ich auch per se eine transdisziplinäre Forscherin.“
Dr. Netaya Lotze
Eigene Projekte zu Kohärenz und Kohäsion in KI-Dialogen
Einführung für Studierende
Dr. Netaya Lotze Publikationsprojekt (in Vorbr.):
„Linguistische KI-Forschung – Eine Einführung (Narr)“
Die Einführung stellt als erste ihrer Art das Feld des neuen Forschungsbereichs der linguistischen KI-Forschung in seiner vollen Breite vor und leistet damit einen Beitrag zur kritischen Reflexion neuer medialer Kontexte innerhalb der Digital Humanities. Das Buch richtet sich also an Studierende der Geisteswissenschaften – besonders der Philologien und Linguistiken – eignet sich aber auch für interessierte angehende Medienwissenschaftler*innen und Informatiker*innen, die ihre Perspektive auf KI-Forschung erweitern wollen. Auch für Praktiker*innen im Bereich Dialog-Design und KI-Entwicklung stellt die geplante Einführung eine Bereicherung dar, obwohl der thematische Fokus des Buches mehr auf der Seite der Grundlagenforschung zu dieser neuen Form von Dialogizität liegt als auf praktischen technischen Anwendungen.
In Online-Diskursen (Schriftlichkeit)
Dr. Netaya Lotze und Laura Orhndorf in Kollaboration mit Dr. Timo Kaerlein (Kommunikationswissenschaften, Siegen) (in Vorbr.):
„Logische Kohärenz und Filterblaseneffekte in Social Bots“
Im Band wird eine qualitative Erstbescheibung von logischer In- oder Quasikohärenz in Dialogen mit Social Bots vorgenommen (Ohrndorf & Lotze) und deren Wirkung vor dem Hintergrund von Netzwerkeffekten der Social Media interpretiert (Kaerlein).
Mit Kindern
Dr. Netaya Lotze „KIDS-Projekt“ (und Nachfolgeprojekt in Planung)
KIs mit Sprachinterface werden in näherer Zukunft vermehrt in Schulen, Kindergärten und als interaktives Spielzeug in die Lebenswelten unserer Kleinsten vordringen. Inwiefern Kinder sprachlich auf die KIs reagieren, ist auf linguistischer Ebene noch kaum (für das Deutsche gar nicht!) untersucht. Dabei kann von den momentanen, noch äußerst störungsanfälligen Systemen, die nur isolierte Frage-Antwort-Sequenzen ausgeben und keinen kohärenten Dialog mit semantisch logischem „roten Faden“ entwickeln, aus linguistischer Perspektive durchaus eine Gefahr für User*innen im Kindesalter ausgehen, deren Erstspracherwerb noch nicht abgeschlossen ist. Unsere Studien zeigen, dass a) Erwachsene versuchen, KIs gegenüber logische Kohärenz über längere Dialogsequenzen aufzubauen, indem sie sich auf (vermeintlich) geteiltes Wissen berufen (und scheitern) („Grounding“ Lotze 2016, Fischer 2006) und b) Kinder noch hartnäckiger auf Etablierung einer gemeinsamen Wissensbasis („Common Ground“) mit der KI beharren und sich in ihrem Vokabular (lexikalisch und syntaktisch) dem System anpassen (Lotze 2019).
E-Learning
BMBF-Kooperationsprojekt mit FH Münster (Prof. Dr. Gernot Bauer, Institut für Gesellschaft und Digitales GUD)
Projekt: „ALFA-Bot“
Start: Dezember 2020
Das Projekt strebt die Konzeptionalisierung und Gestaltung einer E-Learning Umgebung mit Chatbot in Leichter Sprache zur Unterstützung der Alphabetisierung an. ALFA-Bot wird über eine multimodale Lernumgebung mit medial-mündlichem Sprachinterface verfügen. Durch Erprobung und Evaluation der Technologie sollen neue Erkenntnisse über niedrigschwellige Angebote für Menschen mit Alphabetisierungsbedarf gewonnen werden.
ALFA-Bot ist als interdisziplinäres Projekt zwischen Informatik und Linguistik angesiedelt, um von Entwicklungsbeginn an linguistisch sinnvolle Aufgaben zu konzipieren und ein möglichst natürliches, kohärentes und intuitiv nutzbares Dialog-Design für das Sprachinterface zu gestalten.
Promotionsprojekte zu Kohärenz und Kohäsion in KI-Dialogen
Mit Assistenzsystemen (Oralität)

Promotionsprojekt Anna Greilich, M.A. (in englischer Sprache)
Betreuung: Lotze, Dimroth
“Information structure in human-computer interaction: Requesting information from Amazon Alexa vs from a human-interlocutor”
Anna Greilich (WWU Münster)
anna.konstantinova@uni-muenster.de
In human-computer interaction (HCI), we model our utterances based on the expectations about the system’s knowledge and performance which is often inconsistent and unpredictable. Very little is known about how common ground is being managed in the such unpredictable dialogues with AI-based systems like Amazon Alexa, Cortana and Siri. The present ongoing dissertation project aims at shedding light at how the users linguistically mark focused vs given information in requests addressed to Amazon Alexa (HCI condition) and a confederate speaker (HHC baseline condition).
Based on the dataset collected from 20 speakers of German from Munster area, I am analyzing information structure with the focus on the following aspects: 1) the choice of referring expressions, 2) syntactic position of the given and focused information, and 3) prosodic marking of given and focused information. The data was elicited with the help of stimuli shown on the computer screen during the interaction. The procedure allowed to partially control the dialogue-flow and vary the givenness of the requested information.
The preliminary results show significant differences in the choice of referring expressions in HCI and HHC (see Fig. 1). In dialogue with Amazon Alexa, the participants tend to use full names when referring to both given and new information. In dialogues with a confederate speaker, in contrast, the participants use various referring expressions: from accented/defined full names to omission of the salient information.

Fig.1: Coding system for the scores given to referring expressions in the utterances by Amazon Alexa, Confederate speaker, and participants in HCI and HHC condition. The boxplots show the mean scores of the referring expressions in the data from 14 participants.
The syntactic analysis should show how the lack of pronominalisation and omission influences syntactic structures in requests for information in HCI. Another factor which influences the syntactic structure of requests is a high number of attempts to be understood by Alexa after the miscommunication occurred. Reformulations might lead to a more considerable syntactic variation in the position of the given and focused constituents in the requests.
The pilot analysis of the prosodic patterns was conducted based on the data from one participant. The preliminary results suggest the significant differences between pitch max and pitch min measurements on the main topic and focus in the utterances addressed to Amazon Alexa and a confederate speaker. The overall F0 measurements were higher F0 for HCI compared to HHC for given (the main topic) and focused information (see Fig. 2-5).
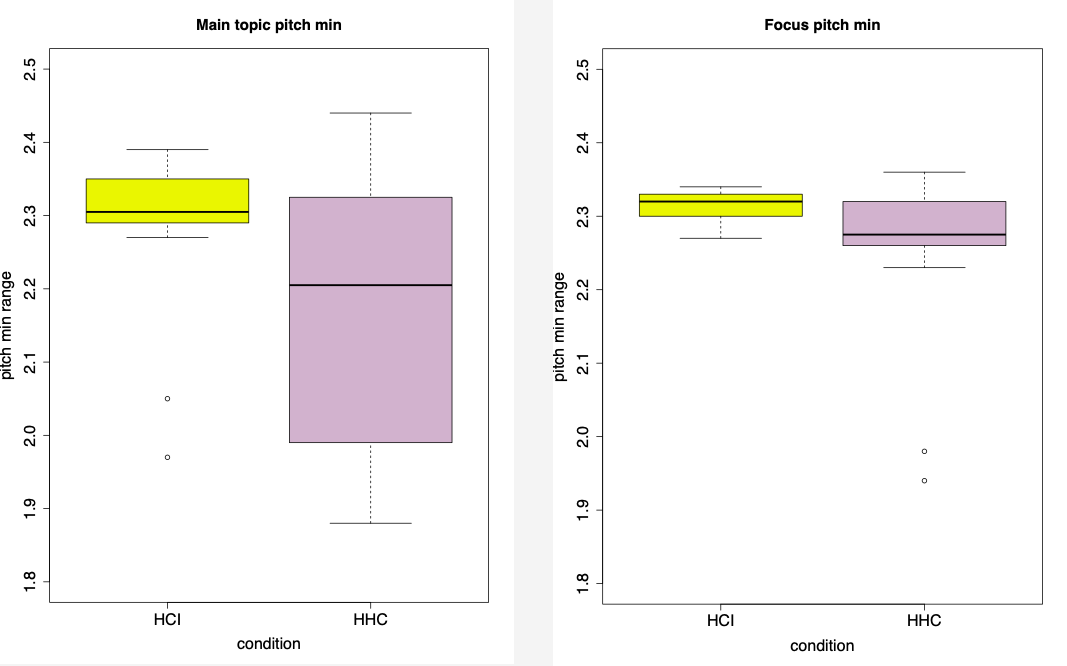
Fig. 2-3: The difference between the pitch min in the prosodic marking of the main topic and focused information in HCI and HHC.
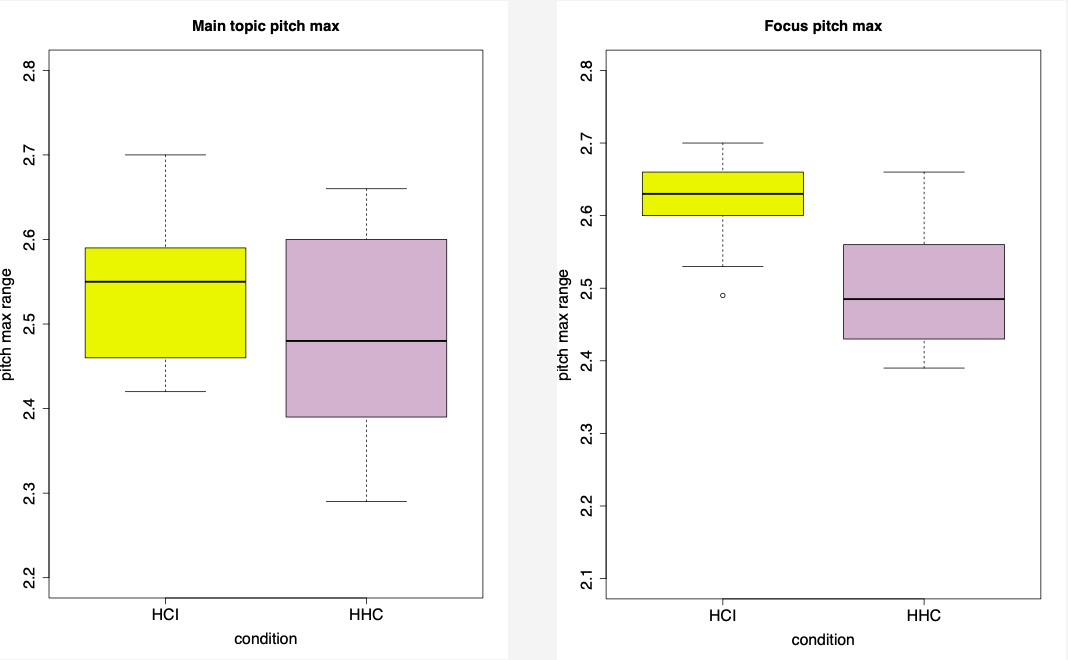
Fig. 4-5: The difference between the pitch max in the prosodic marking of the main topic and focused information in HCI and HHC.
Nach oben
Promotionsprojekt Yannick Frommherz, M.A. (in englischer Sprache)
“Alignment in German human-voice assistant interaction”
Yannick Frommherz (TU Dresden)
yannick.frommherz@tu-dresden.de
Alignment beschreibt das psycholinguistische Phänomen, dass Gesprächspartner sich innerhalb einer Interaktion auf verschiedenen linguistischen Ebenen einander angleichen, z.B. auf der lexikalischen Ebene: Wenn Sprecherin A den Ausdruck x einführt, um eine Entität zu referenzieren, so ist es wahrscheinlich, dass ihre Gesprächspartnerin B ebendiesen Ausdruck x aufgreift, um auf dieselbe Entität zu verweisen (Pickering & Garrod, 2004; Szmrecanyi, 2005; Koulouri et al., 2016). Diese Tendenz wurde sowohl für die Mensch-Mensch-Interaktion (Branig, M-an et al., 2000) als auch für die Mensch-Maschine-Interaktion gezeigt, unter anderem für Lexik (Branigan & Pearson, 2016; Huiyang & Min, 2022), Syntax (Heyselaar et al., 2017) und Prosodie (Raveh et al, 2019) sowie für verschiedene Settings wie Interaktionen mit Chatbots (Lotze, 2016), Robotern (Fischer, 2016) und Sprachassistenten (Linnemann & Jucks, 2018).
Der Großteil der Forschung zu Alignment in Mensch-Maschine-Interaktion ist experimenteller Natur, wobei vorwiegend die sog. picture-naming-matching-task, i.d.R. als Wizard-of-Oz-Setup, zum Einsatz kommt. Dabei tauschen Probandinnnen und Maschine (bzw. als Maschine getarnter Mensch, d.h. ein Wizard) abwechselnd Beschreibungen von Bildern aus, die der jeweils andere einem Bild unter mehreren zuordnen muss. In der Beschreibung der Maschine verbergen sich sprachliche Elemente (z.B. eine passive Konstruktion), zu denen die Probandin in ihrer Beschreibung dann (unbewusst) alignt oder nicht (Pearson et al., 2006, Heyselaar et al., 2017). Während dieses Design gut kontrollierbar ist, emuliert es ein Szenario, das fernab von realer Mensch-Maschine-Interaktion steht, was die ökologische Validität solcher Erkenntnisse herabsetzt. Auf der anderen Seite, kann eine korpusbasierte Herangehensweise Alignmentprozesse im Gehirn nicht direkt nachweisen, sondern nur die Persistenz linguistischer Strukturen aufzeigen (Lotze, 2016). Gleichzeitig bietet sie den Vorteil, dass (einigermaßen) authentische Interaktionen zwischen Menschen und tatsächlichen Maschinen ausgewertet werden können. Nichtsdestotrotz gibt es kaum korpusbasierte Forschung zu Alignment in der Mensch-Maschine-Interaktion. Eine löbliche Ausnahme ist Lotze (2016), die das Thema in Interaktion zwischen Menschen und Chatbots analysierte und umfassende Belege für lexikalische und syntaktische Persistenz fand. Was noch komplett fehlt, ist korpusbasierte Forschung zu Persistenz in der Interaktion zwischen Menschen und Sprachassistenten, die in der Gestalt von Siri und Alexa immer weiter verbreitet sind (Byrne et al., 2019; Yuan et al., 2020). Dieses Dissertationsprojekt zielt darauf ab, diese Forschungslücke zu füllen, indem mehrere deutschsprachige Korpora mit Interaktionen zwischen Menschen und Alexa auf Persistenz hin untersucht werden.
Nach oben
„PROJEKTE AN DER UNIVERSITÄT DER HANSESTADT HAMBURG (UHH)“
Supervisor des interdisziplinären Studierenden-Projekts „Die Fragende KI“ (DAAD und BMBF)
Mitarbeitende:
- Ben Müller – Studentischer Leiter und Gewinner des Hackathons #Semesterhack2 2021 (UHH)
- Judith Tripp (WWU)
- Helena Budde (damals WWU, jetzt IDS Mannheim)
Vorstellungs-Video: https://youtu.be/DBz2G__hYOY
Projekt-PDF: Projektvorhaben_QAI_BMBF_1_
„PROJEKTE AN DER LEIBNIZ UNIVERSITÄT HANNOVER (LUH)“
| 2013 – 2015 | „Twifferences – detecting and computing linguistic varieties on Twitter“: interdisziplinäres Projekt / Linguistik / Informatik (Kooperation der LUH mit dem Forschungszentrum für Web Sciences L3S und der University of Hertfodshire), interne Projektleitung |
| 2010 – 2012 | „Microblogs global“: Sprachvergleichende Analyse von Tweets, wiss. Mitarbeiterin (Ltg. Prof. Dr. Schlobinski) |
| 2012 | „Audio-Coding of Linguistic Data“: Neurolinguistische Studie zur auditiven Perzeption, wiss. Mitarbeiterin (Kooperation mit Fraunhofer Institute for Integradted Circuits (Ltg. Dr. Schinkel-Bielefeld) |
| 2009 – 2011 | „El Lingo – eine interaktive Lernplattform“: E-Learning-Projekt, Gestaltung eines Chatbots als virtuellen Tutor für mediensprache.net (Finanzierung Leibniz KIQS), wiss. Mitarbeiterin (Ltg. Dr. Siever) |
| 2008 – 2010 | „Meaningful Changes“: Neurolinguistische Studie zur kognitiven Verarbeitung von Chat-Beiträgen (Kooperation mit MPI Leipzig, Universität Marburg, Universität Mainz), wiss. Mitarbeiterin (Ltg. Prof. Dr. Bornkessel-Schlesewsky, Prof. Dr. Schlesewsky) |